这篇文章介绍了我近期的工作,一个端到端的手势识别模型。
Introduction
识别手势在智能交互系统领域是一个基本研究课题。能够快速识别出用户的手势并做出反应对智能交互系统的用户体验有很重要的作用。手势识别在安全、K12教育、工业领域都有广泛的应用。
本文介绍一个端到端的手势识别系统的模型。这个模型的输入是一张240*320 的 RGB 图像,输出是6种预定手势的概率。我们取概率最大者为预测的手势类型。
我们定义如下的6种手势:

Data
模型的输入数据是由60个经过标注的视频数据采样而来。一共有10个人,每个人6个视频对应6种不同手势。我们对每一帧采样,共获得11996张图片。Train、validation和Test的划分比例是6:2:2,并且经过shuffle。
Model
结构
我们定义如下的模型结构。网络的前部是CNN与Maxpooling的多个组合用来提取特征,构造feature map。网络的尾部是两个Dense层,用来输出6种手势的类型。
def End2endNet(pretrained_weights=None, input_size=(240, 320, 3)):
inputs = Input(input_size)
conv1 = Conv2D(80, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
pool1 = MaxPooling2D(pool_size=(2, 2), strides=[2, 2])(conv1)
conv2 = Conv2D(160, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool1)
pool2 = MaxPooling2D(pool_size=(2, 2), strides=[2, 2])(conv2)
conv3 = Conv2D(320, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool2)
pool3 = MaxPooling2D(pool_size=(2, 2), strides=[2, 2])(conv3)
conv4 = Conv2D(640, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool3)
drop4 = Dropout(0.25)(conv4)
conv5 = Conv2D(320, 3, activation='relu', padding='same', kernel_initializer='he_normal')(drop4)
pool5 = MaxPooling2D(pool_size=(2, 2), strides=[2, 2])(conv5)
Flat5 = Flatten()(pool5)
Dense6 = Dense(160, activation='relu', kernel_initializer='he_normal')(Flat5)
Dense7 = Dense(6, activation='softmax')(Dense6)
model = Model(inputs=inputs, outputs=Dense7)
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
if pretrained_weights:
model.load_weights(pretrained_weights)
return model
Loss function
这是一个多分类问题,我们采用了 categorical_crossentropy 为loss function.
Activation function
网络前面的CNN层的Activation function都是 relu, 最后一个Dense层的Activation function是 softmax.
模型可视化
模型看起来如下图所示。细心的读者可能发现网络结构和UNET很像。是的,我们直接UNET作者的画图风格绘制网络结构图。

训练
这里我们给出Quick start
- 首先给你的环境安装合适的Opencv
-
git clone this project 并 安装依赖
git clone https://github.com/nanguoyu/End2end-model-for-hand-gesture-recognition.git
cd End2end-model-for-hand-gesture-recognition
pip install -r requirements.txt
- 下载训练数据
注意 受隐私原因,目前我们暂不提供数据下载。我们会在解决隐私问题后,补充该脚本。
python DownloadData.py
- 训练这个模型
python train_End2end.py
测试
python test_end2end.py
这会开启你的摄像头设备,你可以尝试6种手势。模型会给出最大概率的手势和概率值。
一个 Demo 视频在Youtube
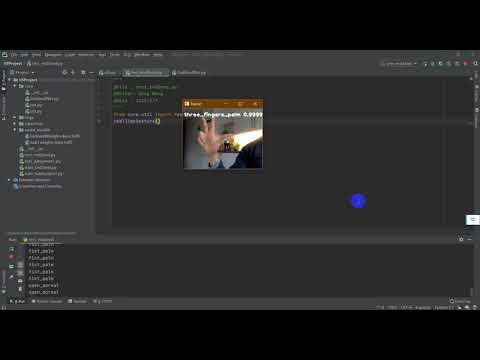
一个 Demo 视频在Bilibili
结果
训练集的准确率是100\%, 测试集的准确率是98.62\%. 这个结果看起来很好,但实际上是过拟合的,因为数据集太小了。我们的模型只被允许在10个人的视频数据上跑。

文章评论
1w多长图片,打标怎么完成的? 人工打标会不会 效率太低了?
@yulf Hi yu, 你好。我们当时做时,原始数据是视频,可以对关键帧打标,相邻关键帧之间的标注位置/手势的固定不变,如果中间变化过大,则加入关键帧修改标注即可。最后按帧导出所有图片即可。